Unity Shader 延迟渲染(翻译十三)
本篇摘要:
- G-Buffer
- HDR与LDR
- Deffered反射
Deferred Rendering Path
到目前为止一直使用了Unity的Forward Render Path,现在开始学习Deferred Path,以及对比这两者间的差异
准备工作
- 通过Edit/Project Setting/Graphic切换Render Path;
- 关闭环境光、反射光;
- Quality设置阴影质量为最高,方便观察;
- 启用dynamic batching
开始对比Draw Calls
一共有64个Object可见物体组成一个Prefab。
通过对比这个prefab有和没有阴影,分别计算处于ForwardPath和DeferredPath下的Draw Call数。
1. No Shadows
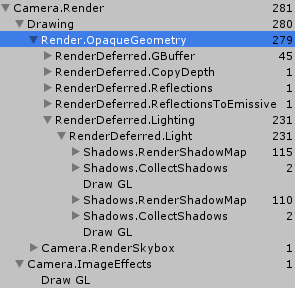
没有阴影下,128次几何绘制加1次Clear;1次天空盒绘制;2次屏幕处理绘制,总共132次Draw Call。(如果是使用一个方向光,动态批处理就会生效,就可以少于64个批次绘制)。然而由于有一个额外的方向光,dynamicBatching就不会生效,所以总共绘制两遍。
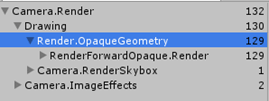
2. Enable Shadows

启用阴影后,需要更多的Draw Calls去生成阴影纹理,分析如下:
首先,填充depth-buffer,需要47次Draw Call,47少于64得益于dynamicBatching;
其次,创建Cascading阴影纹理。第一个光提交了110次Drall Call,同时第二个光提交了115次Drall Call,这些纹理渲染在屏幕空间screen-space buffer,执行过滤。
最后,每个光绘制一次几何物体,用了128=$(64*2)$次DC。
总共408次Draw Calls。
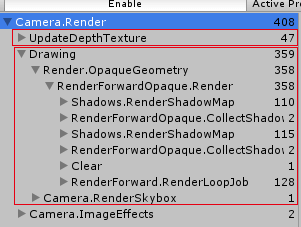
上面是分析前向渲染,下面是分析延迟渲染。
1. No Shadows
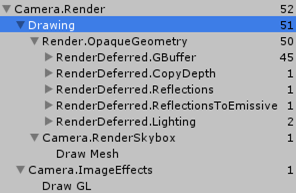
首先,45次Draw Call渲染GBuffer,这得益于dynamic Batching;
其次,1次Draw Call复制深度纹理;
接着,1次绘制反射和1次自发光反射;
最后,2次光照着色(两个方向光)。
总共52次 = 49次几何绘制; 1次天空盒绘制;2次屏幕处理绘制
2. Enable Shadows
与上图的lighting着色不同,用231次Draw Calls绘制。但是其阴影绘制方法与Forward模式是一样的。
1
2
3
4
5
Deferred不支持MSAA,如果启用Camera组件会有Warning
延迟着色依赖于每个片段存储的数据,这是通过纹理完成的。 这与MSAA不兼容,因为该抗锯
齿技术依赖于子像素数据。 尽管
三角形边缘仍然可以从MSAA中受益,但延迟的数据仍会混叠。 您必须依靠一个后处理过滤器来进行抗锯齿。
分析1.2的对比数据
| 结论 | 当渲染多个light光时,Deffered着色模式比Forward着色模式的渲染效率更高! | ||
| 相同 | 两个模式的阴影绘制方法一样 | ||
| 差异 |
|
缘由以及deferred着色解释:
要渲染物体,需要抓取它的Mesh数据;转换到正确的空间;插值传递数据;检索properties数据;计算光照。对于Forward shaders:对要着色的物体的每个像素重复上述步骤;additivePass要比basePass节省,是因为depth-buffer已经提前准备好,同时它不需要关心间接 光;但它任然会重复在basePase已经完成的有大量工作。
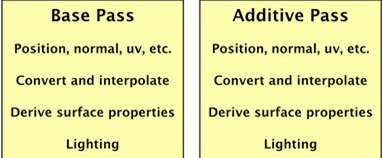
既然每次计算的几何性质都是一样的,可以让basePass计算后将它们存储在一个缓冲区中。然后,additivePass可以重用数据,消除重复的工作。要存储这些片段的数据,就需要一个适合的缓冲区,就像深度和帧缓冲区一样。

现在,缓冲区中提供了照明所需的所有几何数据。 唯一缺少的是灯光本身。 但这意味着我们不再需要渲染几何体,仅需渲染光就足够了。 此外,basePass只需要填充缓冲区,然后推迟所有直接光照着色计算。这就是延迟着色。

deferred下多光源如何使用
当使用一个光源,deferred着色本身没有多大好处。但是当使用很多光源时,每额外增加一个光只会少量增加一点工作,前提是该光源不投射阴影。
因此,当几何物体和光源分开渲染,光的数量对物体的影响是没有限制的,所有的光对它们范围内的物体都是逐像素着色,这个_Pixel Light Count_也就没用了。


多个实时光源,也可以用bake替代。
光源如何渲染分析
光本身是如何渲染的?
1、directional方向光,它被渲染成一个面片(Quad)覆盖整个屏幕,使用_Internal-DeferredShading_ shader完成渲染.
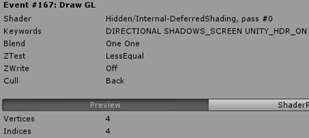
该shader使用了_UnityDeferredLibrary.cginc_的UnityDeferredCalculateLightParams函数计算光照。
1
**对于SpotLight、PointLight类似,不同在于它有自身的照明范围。**
2、SpotLight首先要渲染成一个类似金字塔体Mesh。
首先,使用Internal-StencilWrite shader渲染该金字塔Mesh并写入模板缓冲区;
然后,用该缓冲区与稍后将渲染的片元比对,是否要屏蔽体积范围外的片元光照计算。
目的:处于体积范围内的片元将被计算光照、阴影,体积范围外的不需要计算,如果这个金字塔内一个片元被渲染,它会执行光照计算。防止那些不必要的光照计算降低开销。
原因:光线无法到达那里。
注意,当光的体积与相机的近平面相交则该方法失效。

3、PointLight使用类似方法,区别在于它被渲染成球体Mesh。

分析什么是G-Buffers
缓存数据的缺点就是要存储。deferred渲染使用了multiple render texture实现(MRT),这些纹理就是G-buffers。
deferred要求4个G-Buffers,合并后每个像素总位数:LDR160位,HDR192位。这比起32位大多了,所以对于移动GPU有限制,桌面则没问题。
是哪四个纹理?
打开frame Debugger或点击Scene/top left下拉菜单选择Deferred选项
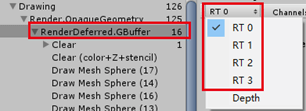

Albedo-对应RT0;典型代表diffuse color
Specular–对应RT1;典型代表specular + roughness
Normal-对应RT2;典型代表normals
Emission–对应RT3;典型代表emission + reflection
混合使用Deferred与Forward渲染模型

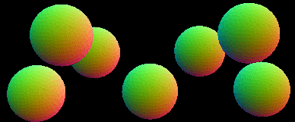
首先,执行deferred渲染G-buffer,数据存到G-buffer缓冲区。在这渲染期间,forward模式下的物体不参与渲染,不可见。


接着,渲染forward depth,同样存到G-buffer缓冲区。由于是forward所以输出黑色轮廓,覆盖了之前的片元。


开始写Deferred Shader
增加一个Pass,指定光照标签Light Mode = “Deferred”,pass的顺序不重要。
1
2
3
4
5
Pass {
Tags {
"LightMode" = "Deferred"
}
}

完整版的着色
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Pass {
Tags {
"LightMode" = "Deferred"
}
CGPROGRAM
#pragma target 3.0
#pragma exclude_renderers nomrt//(对于不支持MRT设备禁用该pass)
#pragma shader_feature _ _RENDERING_CUTOUT
#pragma shader_feature _METALLIC_MAP
#pragma shader_feature _ _SMOOTHNESS_ALBEDO _SMOOTHNESS_METALLIC
#pragma shader_feature _NORMAL_MAP
#pragma shader_feature _OCCLUSION_MAP
#pragma shader_feature _EMISSION_MAP
#pragma shader_feature _DETAIL_MASK
#pragma shader_feature _DETAIL_ALBEDO_MAP
#pragma shader_feature _DETAIL_NORMAL_MAP
#pragma vertex MyVertexProgram
#pragma fragment MyFragmentProgram
#define DEFERRED_PASS
#include "MyLighting_SemitransparencyShadow.cginc"
ENDCG
}
4个g-buffer输出
要填充4个缓冲区需要为Fragment支持两种输出格式;然后修改Fragment函数返回值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
struct FragmentOutput {
#ifdef DEFERRED_PASS
float4 gBuffer0 : SV_TARGET0;
float4 gBuffer1 : SV_TARGET1;
float4 gBuffer2 : SV_TARGET2;
float4 gBuffer3 : SV_TARGET3;
#else
float4 color : SV_TARGET;
#endif
};
FragmentOutput MyFragmentProgram(Interpolators i){
FragmentOutput output;
UNITY_INITIALIZE_OUTPUT(FragmentOutput, output);//不加这句会有warning
#ifdef DEFERRED_PASS
#else
output.color = color;
#endif
return output;
}
计算Buffer 0
该g-Buffer一般用来计算diffuse albedo和surface occlusion,这是ARGB32格式纹理。
diffuse存在RGB通道,occlusion存在A通道。
1
2
3
4
#if defined(DEFERRED_PASS)
output.gBuffer0.rgb = albedo;
output.gBuffer0.a = GetOcclusion(i);
#else


计算Buffer 1
该g-Buffer一般用来计算specular albedo和smoothness,也是ARGB32格式纹理。
specular存在RGB通道,smoothness值存在A通道。
1
2
output.gBuffer1.rgb = specularTint;
output.gBuffer1.a = GetSmoothness(i);
计算Buffer 2
该g-Buffer包含了世界空间法线向量,存在RGB通道,是一个ARGB2101010格式纹理。Alpha占2位,RGB各占10位。这意味着该向量的每个标量占10bits而不是之前的8位,也就有更精确。alpha通道不用,默认位1.
1
output.gBuffer2 = float4(i.normal * 0.5 + 0.5, 1);


计算Buffer 3
该g-Buffer被用来计算场景光照,纹理格式依赖于相机设置的HDR或LDR。LDR是ARGB2101010格式。HDR是ARGBHalf格式,每个通道存储16位单精度浮点数,共64位。因此HDR版本比其他buffers大两倍内存。只用到了RGB,Alpha默认为1。
1
output.gBuffer3 = color;
上面使用的color颜色已计算过阴影,需要使用DEFRRED_PASS重新计算;同时关闭light.ndotl计算;在GetEmission也要使用DEFRRED_PASS标签
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
output.gBuffer3 = color;
UnityLight CreateLight (Interpolators i) {
UnityLight light;
#if defined(DEFERRED_PASS)
light.dir = float3(0, 1, 0);
light.color = 0;
#else
//...
#endif
~light.ndotl = DotClamped(i.normal, light.dir);~
return light;
}
float3 GetEmission (Interpolators i) {
#if defined(FORWARD_BASE_PASS) || defined(DEFERRED_PASS)
...
#else
return 0;
#endif
}

Ambient Light

输出四个Buffers后结果看起来较好,但是还不够完整,还缺少环境光。环境光与自发光都没有单独的pass计算,都需要在g-buffers填充后附加到最终颜色值上。环境光是间接光,在间接光函数计算DEFERRED_PASS

光源范围-LDR与HDR分析
对于Internal-DeferredShading shader,Camera组件启用或关闭HDR:
启用HDR,则不执行pass 1,pass 0 fragment返回half4精度,纹理格式ARGBHalf。每个通道存储16位单精度浮点数,总共64位。
关闭HDR后,使用LDR计算策略。在pass 0 fragment会返回fixed精度,使用exp2(x)_[exp2(x)=2-x]_对数编码lightBuffer,获取到更大的颜色范围;pass 1则使用log对数解码buffer数据到主纹理上,纹理格式为ARGB2101010。Alpha占2位,RGB各占10位。
HDR 与 LDR
开启HDR模式下,Deferred与Forward着色效果几乎相似。但是在LDR模式下,Deferred着色就是错误的。

在上图描述中,Unity会使用exp2(x)编码LDR数据,所以对自发光和环境光也要使用exp2(x)编码。
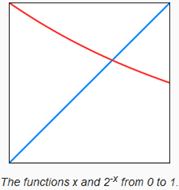
1
2
3
4
5
6
7
8
9
10
#pragma multi_compile _ UNITY_HDR_ON
#if defined(DEFERRED_PASS)
#if !defined(UNITY_HDR_ON)
color.rgb = exp2(-color.rgb);
#endif
...
#else
output.color = color;
#endif

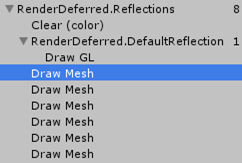
Deferred Reflections
展示不同渲染模式下的,探针照射区域过渡对比。下图显示了每个反射可混合多个反射探针。
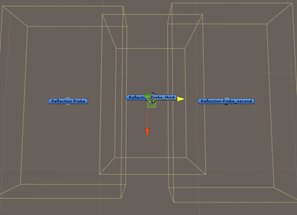


逐像素照射
延迟模式的不同之处在于:探测不会针对每个对象进行混合。而是按像素混合的。这是由internal-deferred shader完成计算。图3右很明显,大地板镜子,延伸到结构之外后,它的渲染范围很小。
Forward模式下:
地板被迫在整个表面使用reflection探头。结果,boxProjection探射到的投影在box外面也显示。也能看见它和其他探针混在一起。图3左。
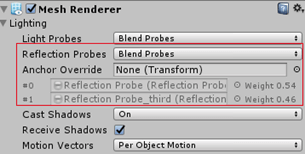
Deferred模式下:
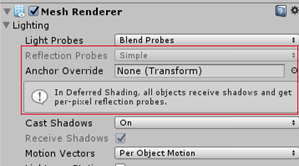
reflection只渲染box size范围,探射的范围被投射到与boxProjection相交的面积。所以reflection的反射不会超出给定BoxSize范围。实际上,边缘消失的时候也会延伸一点。其他两个探头也是如此。
渲染reflection所用方法,与渲染lights类似:
首先,使用Internal-StencilWrite shader渲染box size大小的Mesh并写入模板缓冲区;
然后,用该缓冲区与稍后将渲染的片元比对,是否要屏蔽体积范围外的片元。

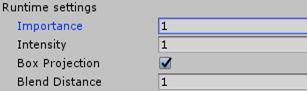
Importance决定各reflection的渲染先后顺序;Intensity决定了反射强度:默认为1,最小为0,大于1过曝。Forward下是整个接收面积;Deferred下是相交面积。下面谈Blend Distance。
Blend Distance
Deferred下探针体积边缘有过渡混合,由Blend Distance决定。该值默认为1,只有Deferred模式可调。
多个probes相交时,边缘过渡混合非常有效。也可以用来增大探射体积范围。

Deferred Pass下的反射
虽然deferred很有效,并且每个物体可以混合两个以上的探针。
也有缺点:不能使用锚重写来强制对象使用特定的反射探测。有时这是确保得到正确反射的唯一方法。可以先禁用内置Deferred Refelection,
打开frame Debugger查看G-Buffers RT3,包含了Emission和Refelection

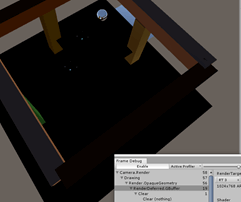
采样黑色探针是浪费。要确保deferred pass只在有需要时采样,用UNITY_ENABLE_REFLECTION_BUFFERS来检查。
1
2
3
4
5
6
7
8
UnityIndirect CreateIndirectLight (Interpolators i, float3 viewDir) {
#if defined(FORWARD_BASE_PASS) || defined(DEFERRED_PASS)
#if defined(DEFERRED_PASS) && UNITY_ENABLE_REFLECTION_BUFFERS
indirectLight.specular = 0;
#endif
#endif
return indirectLight;
}